
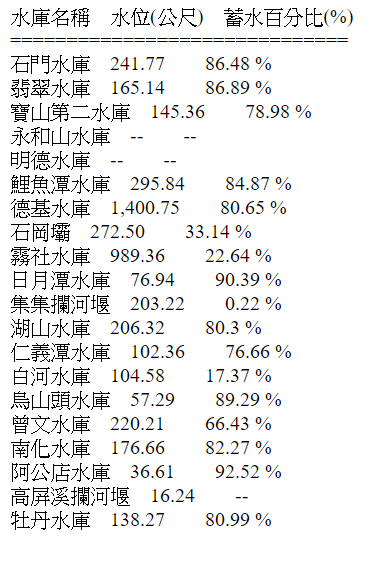
import urllib.request as req
url="http://fhy.wra.gov.tw/ReservoirPage_2011/Statistics.aspx"
with req.urlopen(url)as response:
data=response.read().decode("utf-8")
import bs4
root= bs4.BeautifulSoup((data.replace('<br>','')).replace('<br/>',''),"html.parser")
//把文件裡的空格替換掉
up=root.find("th", string="水庫名稱")
print(up.string)
up2=root.find("th", string="水位(公尺)")
print(up2.string)
up3=root.find("th", string="蓄水百分比(%)")
print(up3.string)
with open ("haha.html", mode="w", encoding='UTF-8')as f:
f.write(up.string+" "+up2.string+" "+up3.string+"<br />"+"==============================<br />")
i=0
k=0
z=0
td =root.find_all("td" ,align="right")
a = root.find_all('a', target="chart")
for row in td:
i=i+1
if(i==12):
z=0
i=0
k=k+1
for title in a:
with open ("haha.html", mode="a", encoding='UTF-8')as f:
z=z+1
if(z==k+1):
f.write(title.string+" ")
break
if i==3 or i==6:
with open ("haha.html", mode="a", encoding='UTF-8')as f:
f.write(row.string+" ")
if(i==6):
with open ("haha.html", mode="a", encoding='UTF-8')as f:
f.write("<br />")
沒有留言:
張貼留言
喜歡我的文章嗎? 喜歡的話可以留言回應我喔! ^^